


✍️ ChatGPT & Co : text and learn
L'offre d'outils de génération de texte a explosé, mais beaucoup se ressemblent sans réelle innovation. Heureusement, de récents développements promettent un avenir plus intéressant...


Clones et simili-clones
C’est avec un regard circonspect que je vois émerger chaque jour de nombreux outils de génération de texte IA et notamment des agents conversationnels IA (d’ailleurs, exit Excel, et place aux sites annuaires type Futurepedia, Future Tools ou Ai Tool Hunt pour suivre ce florilège).
En effet, je m’interroge sur la pérennité de ceux-ci. En termes d’outils généralistes, qu’est ce qui pourrait réellement dépasser ChatGPT, qui plus est désormais combiné à son écosystème de plugins ? Sachant du reste que tous nos outils du quotidien (Suite Office, Google Workplace, etc.) sont en train d’intégrer par défaut le modèle de langage GPT ou équivalent. “ChatGPT est le nouveau “Intel inside””, titrait récemment le média FastCompany, très parlant, non ?
Alors certes, une deuxième catégorie d’outils se développe et offre des fonctionnalités adaptées à des besoins plus ciblés. L’avantage ? Ces modèles spécialisés intègrent des connaissances spécifiques, des terminologies et des règles propres à chaque domaine, ce qui leur permet de produire des résultats plus précis et pertinents.
Prenons, un exemple. Jasper se base notamment sur GPT-4, et grâce au principe du fine-tuning, il a affiné son modèle pour des cas d'utilisation liés au marketing. Son avantage ? Une interface plus conviviale avec des templates prédéfinis pour chaque type de contenu : social ad, article de blog, fiche produit, etc. Autrement dit, pour quelqu’un qui ne sait pas “prompter” c’est une aubaine. Mais je vais quand même me faire l’avocat du diable : au nom d’une productivité toujours plus accrue, ne risque-t-on pas de nous noyer dans un océan de contenus templatisés, avec de fortes similarités et, donc, in fine pas si qualitatifs ? Qui plus est, le “prompting” ne devrait-il pas devenir une compétence essentielle ? Il me paraît certain qu’en apprenant à prompter judicieusement sur des outils généralistes, nous conservons une plus grande flexibilité et la capacité de créer des contenus moins standardisés.
Le fine-tuning au service d’une donnée unique
Reste que le fine-tuning appliqué à des données propriétaires et privées peut peut-être changer la donne. C’est en ce sens que je crois fermement en une voie parallèle qui devrait prendre de l'importance dans les mois et les années à venir : celle du B2B avec des IA adaptées aux besoins et aux données des entreprises. C'est dans cette optique que je considère LLaMA, le rival de ChatGPT poussé par Meta, maison-mère de Facebook, comme un game changer.
Je m'explique : LLaMA offre une approche différente en tant que modèle open source non-commercial. C'est un choix intelligent de la part de Meta, car cela favorise l'adoption et la collaboration autour de LLaMA tout en améliorant son image ternie justement par de nombreux scandales liés à la privacy. Pour autant, la démarche n’est pas altruiste car en le rendant open source, Meta bénéficie d'une intelligence collective pouvant contribuer à l’amélioration des performances de son modèle.
En l’espèce, les entreprises peuvent désormais accéder à ce modèle et l'utiliser comme base pour le fine-tuning, leur permettant de créer des modèles d'IA spécifiques à leurs besoins, à leur secteur d'activité et à leurs données privées. Le mot d’ordre : sin-gu-la-ri-té !
Par ailleurs, LLaMA offre un avantage-clé en matière de confidentialité puisque, contrairement à de nombreuses solutions existantes, son approche open source permet aux entreprises de garder un contrôle plus étroit sur leurs données sensibles. Traditionnellement, lorsque les entreprises utilisent des modèles d'IA transmis par des fournisseurs externes, leurs données peuvent être traitées en dehors de leur environnement sécurisé, ce qui soulève des préoccupations en termes de confidentialité et de protection de la data. Avec LLaMA, les entreprises ont la possibilité de déployer le modèle localement, sur leurs propres serveurs ou systèmes, réduisant ainsi le partage de leurs données avec des tiers.
Source-grounded AI
Au cours des dernières années, nous avons assisté à une course effrénée pour augmenter la taille des modèles de langage dans le but d'améliorer leurs performances et leur capacité à générer du texte. Si les modèles de langage de grande taille (LLM) ont certainement leur utilité, d’autres approches émergent parmi lesquelles celle du “source-grounded AI”.
Le concept : plutôt que de se concentrer uniquement sur la taille du modèle et sur la quantité de données d'entraînement, cette approche vise à donner aux utilisateurs la possibilité de définir un ensemble de sources de confiance pour guider les interactions de l'IA. C'est précisément ce qu’explore le projet Tailwind, présenté lors de la conférence Google I/O 2023, en permettant aux utilisateurs de définir un ensemble de documents sources qui servent de “vérité fondamentale”, de socle, pour façonner les interactions du modèle. Avantage : en donnant aux utilisateurs le contrôle sur les sources de données utilisées par l'IA, la confiance et la transparence envers les systèmes d'intelligence artificielle s’en trouvent renforcées. Par ailleurs, cette approche permet de contourner certains pain points associés aux modèles de grande taille tels que le coût élevé d'utilisation des services cloud ou les problèmes de confidentialité liés à la transmission et à l'analyse des données dans le cloud. De plus, en s'exécutant localement sur les appareils, ces modèles offrent une vitesse et une réactivité accrues.
Créativité artificielle
Au-delà de ces modèles de fine-tuning ou de source-grounded AI, il y a également des outsiders qui entendent bousculer le paradigme existant en repoussant les limites de la créativité des machines et en explorant de nouvelles perspectives dans le domaine de la génération de texte. Contrairement aux approches traditionnelles axées sur la perfection et la précision, certains modèles embrassent ainsi les erreurs, les hallucinations et les inexactitudes pour les considérer comme des leviers de créativité.
Pour rappel, les hallucinations dans le domaine de l'IA se réfèrent à la génération de résultats qui peuvent sembler plausibles mais qui sont soit incorrects sur le plan factuel, soit sans rapport avec le contexte donné. Ces sorties sont souvent le résultat de biais inhérents au modèle d'IA, d'un manque de compréhension du monde réel ou de limitation des données d'entraînement.
En expérimentant avec des mécanismes sélectifs et intentionnellement défectueux, ces modèles peuvent ainsi produire des résultats aussi surprenants qu’inspirants, ouvrant de nouvelles possibilités en matière d'innovation et d'expression artistique.
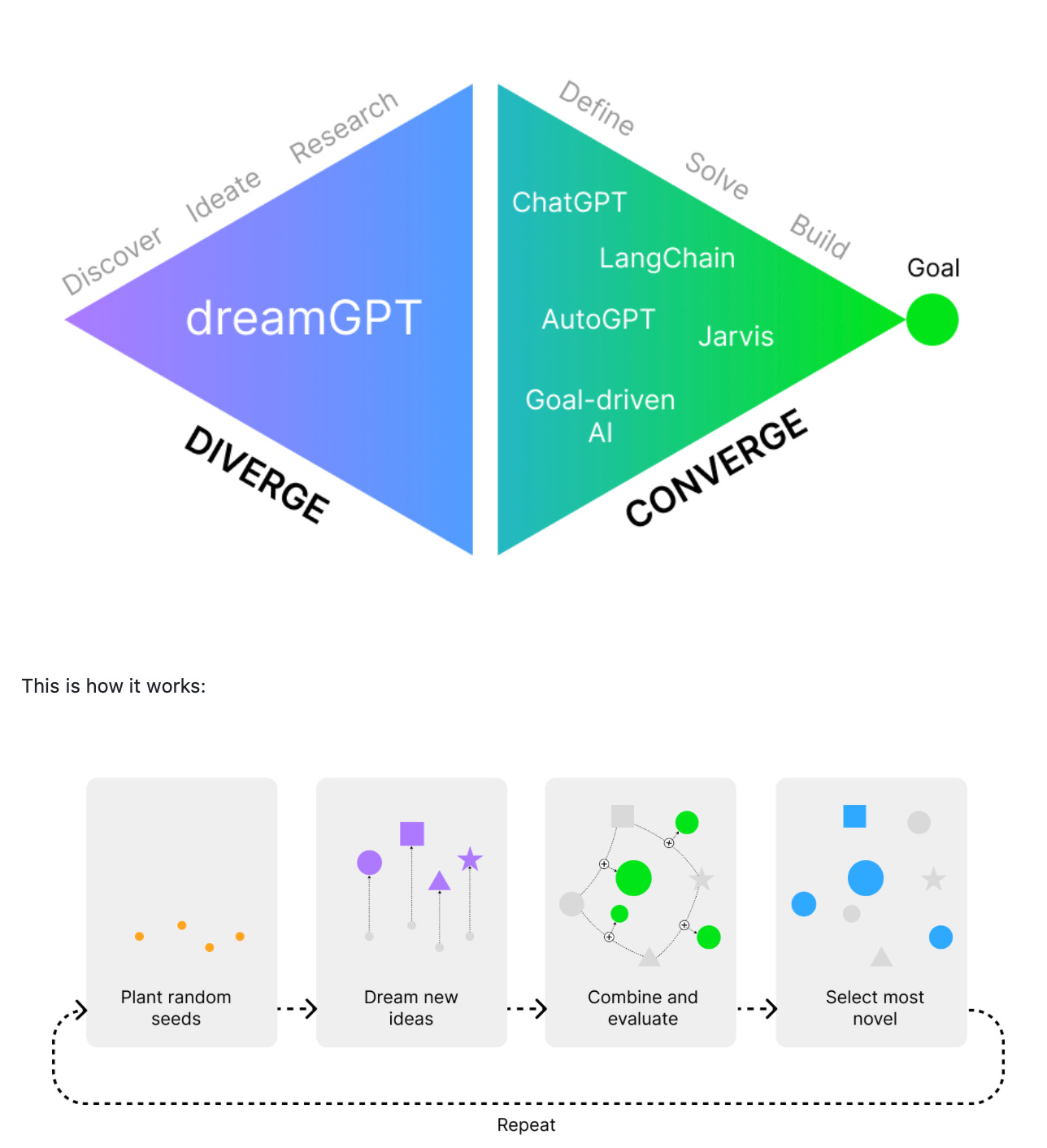
DreamGPT, par exemple, explore cette approche en favorisant la génération de contenu qui pourrait sembler absurde ou incohérent à première vue. Mais en repoussant les limites du raisonnement logique et en embrassant l'ambiguïté, il ouvre de nouvelles voies en matière de génération de contenu.
Démonstration par l’exemple. Prenons la locution de Descartes “Je pense, donc je suis”. Si je demande à ChatGPT de finir cette phrase, toute réponse différente à “je suis” sera considérée comme une erreur. Et pourtant, ce sont précisément tous les jeux de mots autour de cette citation qui, dans un contexte artistique, sont intéressants, et qui, dans certains cas, constituent le style voire la signature d’un auteur. Dans un précédent article, au lieu de titrer l’une de mes sections “Le shopping en fonction de ses valeurs” pour parler de la tendance croissante des sites qui permettent d’effectuer ses achats selon ses convictions (local, éthique etc.), j’avais justement titré “Je shoppe, donc je suis”. Certains me retorqueront qu’en briefant correctement ChatGPT on pourrait obtenir ce même résultat, mais cela nécessiterait une intervention et un guidage constant de l'utilisateur, limitant ainsi la liberté créative et la spontanéité.
Ces modèles outsiders représentent une évolution intéressante dans le domaine de l'IA car ils remettent en question les normes établies et explorent des approches non conventionnelles de la créativité artificielle. Alors que les outils d'entreprise continuent de se concentrer sur l'efficacité et la productivité, ces approches ouvrent la voie à une exploration plus profonde de l'expression artistique, de la pensée divergente et soulèvent des questions fascinantes sur les frontières entre l'humain et la machine. Tout en générant néanmoins quelques préoccupations. Car si je prônais, en décembre dernier, la cultivation de nos imperfections et de nos “contrarian skills” dans un monde aseptisé par l'IA, que devrons-nous faire pour nous démarquer si les IA deviennent elles aussi… imparfaites ?
MD
Au passage, Quentin, Benoit et moi-même avons mis à jour notre rapport sur le futur des contenus, disponible ici.
Chaque fois que je vous lis, Marie, je prends une énorme bouffée de connaissances et un élargissement de conscience ! Je découvre le concept dream GPT qui semble être un champ d'investigation que je n'avais pas vu venir. Merci encore une fois ! Bernard
Madame.
Rédacteur en chef de la revue des pros de la formations en Suisse romande (=francophone), je souhaiterais vous proposer une interview touchant à votre domaine de prédilection.
Je serai à Paris de mercredi à vendredi. Serait-il envisageable de vous rencontrer pour un entretien de +/- 20 minutes?
Dans cet espoir, je vous adresse, Madame,.en plus de mes félicitations pour vos posts toujours très inspirants, mes meilleures salutations.
G. Montangero
journaliste-photographe
Rédacteur en chef de Transfert